數據結構課程設計實踐報告_數據結構課程設計實踐報告免費
導讀 本文將分享滴普科技基于 Data Fabric 的實時湖倉平臺技術實踐。文章將介紹 Data Fabric 的基本原理和概念,并分享滴普基于 Data Fabric 構建的一款產品——FastData。
今天的介紹會圍繞下面四點展開:
1. Data Fabric 介紹
2. FastData 實時智能湖倉平臺介紹
3. FastData 實時智能湖倉平臺實踐案例
4. FastData 實時智能湖倉平臺未來規劃
分享嘉賓|張趙中 北京滴普科技有限公司 架構師
內容校對|李瑤
出品社區|DataFun
01Data Fabric 介紹
首先,讓我們來看一下 Data Fabric 的定義。
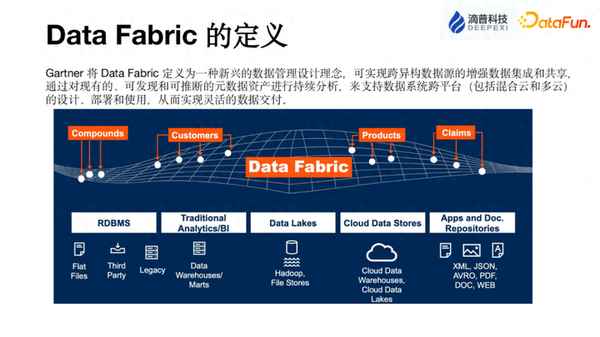
Data Fabric 是一種新興的數據管理設計理念,起源于美國。根據 Gartner 的定義,Data Fabric 可以實現跨異構數據源的增強、數據集成和共享。這意味著以前在構建數據倉庫時需要進行大量的ETL工作,將不同業務關系數據庫中的數據加載到數據倉庫中,并通過各種鏈路進行數據同步。然后,在數據倉庫中進行分層加工,最終生成各種指標,供用戶進行分析和生成報表。
Data Fabric 的理念與傳統的數據倉庫有所不同。在某些情況下,分析師可能并不需要將整個數據完全搬移到自己的工作環境中,而只需要進行簡單的數據探查。因此,Data Fabric 的概念就應運而生。簡單來說,Data Fabric 就是一種對企業內部數據進行輕量級探查的編織概念。
基于Data Fabric 的理念,我們可以進行更加靈活和高效的數據分析。自2019年起,Gartner 已經連續三年將 Data Fabric 技術列入十大數據分析技術趨勢之一。這表明 Data Fabric 技術正在逐漸成為數據管理和分析領域的重要趨勢。在2022年,Gartner 將 Data Fabric 技術列為數據管理和分析領域的排名第一的技術趨勢,它的出現為企業提供了更加靈活和高效的數據管理和分析解決方案,因此備受關注和追捧。
Data Fabric 的價值主要體現在降低成本和提高效率方面。它可以幫助用戶減少在數據開發、分析和管理過程中的工作量,避免頻繁的數據遷移和復制。那么,Data Fabric 實際上解決了什么問題呢?最主要的問題是打破數據孤島。通過將數據接入到統一的平臺中,企業可以獲得對整個企業內所有數據的高級視圖,了解企業內部的數據在哪里、做什么用途。此外,用戶還可以進行簡單的數據探查,而無需將數據全部遷移到數據倉庫或數據湖中。這樣一來,Data Fabric 為企業提供了更加綜合和靈活的數據管理和探索方式,從而提高了數據分析的效率和準確性。
現在硅谷流行一個概念——Lakehouse 數據湖。數據湖和 Data Fabric 的理念密切相關。數據湖強調存儲的易用性,與傳統的數據倉庫不同,它對數據的存儲和拉取要求不那么嚴格,數據的結構和格式也不需要遵循傳統的范式結構化數據的要求。這與數據倉庫的要求有所不同,數據倉庫要求數據必須遵循嚴格的范式結構,并需要進行各種加工處理。因此,數據湖和Data Fabric的理念是密不可分的。
目前,硅谷的一些頭部互聯網公司都推出了基于 Data Fabric 概念的產品。例如微軟在今年五月份推出了 Microsoft Fabric 和 OneLake 兩款產品,它們共同組成了整個數據平臺。IBM 也在5月9日發布了基于 Data Fabric 理念的產品 Watsonx.data lakehouse,與其另一款產品 Cloud Pak for Data 相互關聯,構建了一個從底層到開發應用的全數據加工平臺。微軟的 Fabric 理念是"All your data, all your teams, all in one place",意味著所有數據都可以在一個平臺上進行查看,但并不一定要將所有數據都搬到一個地方。
02FastData 實時智能湖倉平臺介紹
滴普科技基于 Data Fabric 理念打造了一款產品,名為FastData。該產品定位為一站式的實時智能數據湖平臺,主要包含三個層次。首先是我們的 DLink 引擎,解決了在各種云基礎設施上的存儲和計算問題。它有效地組織和存儲數據,并提供了針對不同工作負載的計算能力。在這一層之上,有開發套件和分析套件。開發套件類似于數據開發中的工具箱,提供了調度、編輯器和工作流編排等功能。而分析套件主要解決指標管理問題,更加面向業務,幫助管理各種非 SQL 方式的指標。
湖倉部分是數據倉庫架構中的一個重要組成部分,主要解決數據存儲和計算的問題。在數據倉庫中,數據通常以表格形式存儲,湖倉管理需要考慮如何存儲和管理不同格式的數據表格,以及如何提供加速和管理源數據。在存算分離的情況下,湖倉管理需要提供高效的數據訪問和查詢功能,以便用戶能夠快速獲取所需的數據。
基于 Data Fabric 架構,數據可以分布在不同的位置和系統中,因此湖倉管理需要持有各種數據的源數據,以便能夠更好地管理和查看數據。這樣可以提供更高階的 view 視圖,使用戶能夠更好地了解數據的整體情況。
湖倉管理還提供了一些計算能力和開發套件,用于建模、數據質量、數據治理、調度和數據集成等方面。例如,用戶可以使用開發套件來建立模型、評估數據質量、制定數據治理策略、調度數據處理任務以及實現數據集成。這些工具可以幫助用戶更好地管理和利用數據資源。
最高層的分析層主要解決如何建立各種指標,并通過自己的模型語言來管理這些指標,從而形成企業的數據資產。用戶可以使用分析層來定義和計算各種指標,例如銷售額、用戶增長率、市場份額等。這些指標可以幫助企業更好地了解自己的業務狀況,并制定相應的決策和戰略。
現代數據棧(MDS)是一個全流程架構的概念,它是可組裝的而不是整體式的。每個客戶在使用平臺時,并不需要使用所有的套件,因此 MDS 采用了可插拔的插件形式,根據客戶的需求進行組裝,實現了一種非大而全的平臺。這種可組裝的方式可以降低企業的成本,并簡化平臺架構。MDS 的整個平臺架構從數據源的數據拉取開始,包括實時和離線的數據采集和集成部分,然后將數據集成到數據湖和數據倉庫中,形成湖倉一體的架構。這個架構實現了數據的整合和統一管理,使得企業能夠更好地利用數據資源。總的來說,MDS 是一個靈活可組裝的數據架構,通過插件形式提供所需的功能,覆蓋從數據源到數據湖和數據倉庫的整個數據流程,幫助企業降低成本并簡化平臺架構。
在存儲底座中使用 DLink 套件時,數據開始進行開發,并在開發界面中進行相應的開發工作。在數據開發過程中,數據治理是一個重要的環節,確保數據質量的高標準。然后,數據進入到數據的分析與應用層,這是分析套件所要解決的問題。分析套件提供了一系列工具和功能,幫助用戶進行數據分析和應用開發。
最底層是控制臺,這是另一款產品,其主要解決的問題是對基礎設施的計算資源和存儲資源進行管理。它還提供了監控和告警功能,以及對數據源的統一管理。這個產品被稱為 DCE(Data Control Engine),它的主要目標是管理和優化基礎設施資源,確保系統的高效運行。
產品的核心優勢可以簡單概括為四個方面。首先是低成本,因為它可以完全分離地部署在各種公共云的對象存儲上,同時也支持私有云的部署,比如在 IDC 里面可以對接傳統的 HDFS 等。其次是易用性,它提供了敏捷的數據開發能力,包括低代碼指示和低代碼開發等工具。第三是可組裝性,即根據需求選擇自己的鏈路,這是基于現代數據棧(MDS)的思想,可以根據客戶需求進行定制化部署。最后是簡單擴展性,它是從 Hadoop 生態的大數據平臺向互聯網一體的新一代大數據平臺演進,同時也支持國產化新創,為用戶提供更多的選擇。
概括而言,FastData 具有低成本、易用性、可組裝和易擴展等核心優勢,可以幫助企業更好地管理和利用數據資源,提高數據分析和應用的效率。
FastData 分析套件主要用來處理指標,它采用了統一 ML(Model Language)模型語言來定義、管理和加工指標。一旦指標加工好了,我們就可以將其存儲在各種不同的存儲介質中,包括開源存儲和我們自己的湖倉引擎等。這個分析套件主要關注指標層的存儲和管理,而不關心指標具體存儲在哪里。
為了更好地服務于客戶,我們還提供了各種各樣的服務,包括對接各種 BI 工具、提供數據企業產品 API link 等。客戶可以通過這些服務來查詢指標數據,進行各種數據分析和應用。此外,我們還提供了 AI link 服務,客戶可以通過數據科學和 Jupyter 等工具來訪問指標數據,實現數據應用的開發和部署。
FastData 分析套件統一的指標管理和加工方案,以及豐富的服務和工具,可以幫助客戶更好地利用和應用數據資源,提高數據分析和應用的效率。
分析套件的功能架構主要包括指標語言的建設和指標加速兩個方面。首先,指標語言的建設是指如何定義和管理功能指標。用戶可以使用統一 ML 模型語言來定義復雜的指標邏輯,包括指標的計算、聚合和過濾等操作。這樣可以幫助用戶更好地理解和描述業務需求。
其次,指標加速是非常重要的一點。由于用戶建立的指標邏輯可能非常復雜,我們需要在用戶查詢時能夠快速地找到指標數據。為了實現指標的快速查詢,我們采用了一系列優化技術,包括數據索引、緩存和并行計算等。通過這些加速技術,可以大大提高指標查詢的效率,使用戶能夠快速獲取所需的數據。
分析套件的價值在于提供了無門檻的數據洞察能力,即使不懂 SQL 的人也能夠建立指標。用戶只需要進行簡單的配置,比如配置一些原子指標和修飾詞,然后指定一些加工公式,就能夠計算出所需的指標。通過儀表盤等工具,用戶可以洞察到隱藏在數據背后的業務見解。
另外,統一指標服務是通過模型語言提供各種對外的 API,如 JDBC 和 SDK 等。這樣可以方便用戶通過外部工具訪問和查詢指標數據。此外,CubeLess 是用于構建數據立方體的一種技術。它通過底層的預計算能力和緩存技術,事先計算好指標并加速查詢。同時,分析套件還可以輕松對接各種流行的BI工具,提供加速查詢的能力。
下面重點介紹開發治理套件。開發治理套件是一個相對傳統的數據開發和管理工具,按照常規的數據鏈路進行數據開發。首先,進行數據標準化和建立模型,然后進行數據開發,其中涉及到數據的血緣關系和調度。這個過程涉及到元數據,然后發布到生產環境中進行運行。在這個過程中,還需要進行質量校驗、數據集成和數據安全(如加密和脫敏)等處理,最終對外提供服務。整個流程比較標準化。
最底層的存和算引擎是湖倉引擎,主要解決高效存儲和計算的問題。在存儲方面,我們采用了表格式,主要使用了 Apache 的 Iceberg,并進行了大量的二次開發。在計算方面,我們為不同的工作負載提供了三種內置的算力引擎。對于離線工作負載,提供了 Spark;對于實時工作負載,提供了Flink;而對于機器查詢和分析工作負載,則提供了內置的 Trino 組件。這樣,能夠滿足不同場景下的高效存儲和計算需求。
湖倉引擎的價值主要在于:
首先,能夠提供多工作負載,并能夠以云化方式提供數據服務,也就是它的工作負載。不同的工作負載有不同的內置組件來支撐。
另外,它的架構是存算分離的,它的存儲底座可以對接各種對象存儲,可以提供 PB 乃至 EB 級的海量數據存儲。
分布式數據湖架構,企業可以建立多個數據湖,包括總公司和各個分公司的數據湖。然而,如何實現不同數據湖之間的有效數據共享是一個需要解決的問題。
邏輯入湖與物理入湖是數據管理和分析領域的兩種不同方法。物理入湖是將傳統的數據完全搬遷到數據湖中,并在數據湖上構建數據倉庫或進行數據分析。在物理入湖的過程中,通常會采用批流一體的方式,將離線和實時數據處理合并為一條數據流,以提高數據處理效率。此外,還需要對整個數據集成過程進行管理,包括處理數據結構變更的問題,以確保數據湖中的數據與源數據保持同步。邏輯入湖是一種基于 Fabric 架構的實踐方法。它的主要技術要求是統一元數據,包括已經入湖的數據和未入湖的數據。邏輯入湖并不涉及將數據搬遷到數據湖中,而是通過管理元數據的方式,將元數據撈取過來并進行管理。數據仍然保留在原始位置。在數據倉庫層進行數據加工和分析時,可以直接使用SQL進行操作,無需關心數據的具體存儲位置。
分布式數據湖是一個多湖的概念,它可以解決大型企業中總公司和分公司之間數據交換的問題。以中國移動為例,總公司和各個省分公司都有自己的數據倉庫和數據湖。為了實現數據交換,可以采用分布式多湖聯邦查詢的能力來解決。具體做法是,分公司可以將自己的數據湖注冊到總公司,并提供一個注冊賬號來管理權限。這個注冊賬號可以控制總公司對分公司數據的訪問權限,可以隨時擴大或縮小權限,甚至收回權限。這樣就實現了有限制的數據分享,不需要將所有權限開放給總公司。例如,可以只開放讀權限而不開放寫權限。分布式數據湖的架構主要解決這種情況下的數據交換問題。
分布式數據湖中的核心理念是 Fabric,它能夠實現統一的數據視圖,而這是通過統一的元數據服務來實現的。這個元數據服務不僅可以管理數據湖內的數據,還可以管理企業內其他各種數據存儲的元數據。此外,權限管控也非常重要,因為如果源數據管理沒有權限控制,數據的安全性就無法得到保障。
在 FastData 團隊中負責構建近實時的數倉,是我們的一個重要工作。我們采用了 Apache 的 Iceberg 來做底層的表格式存儲。從數據源到 ODS 層,我們使用 Flink CDC 技術將數據源拉進來,之后從 ODS 層到下面的 DWD 層或 DWS 層,需要讓數據快速地流動起來。為了實現這個目標,我們需要Iceberg這一層支持 CDC 技術,也就是說通過使用Flink這種流式讀取 Iceberg 的 Connector,可以快速地感知上游 Iceberg 表的數據變化和schema變化,并將這些變化及時地同步給下一層。這樣,數據和 DML 就可以不需要人工操作便自動地流動起來。除了 append 數據之外,還有 delete 數據和 update 數據,這些數據都需要通過整個鏈路不停地往下游流動,以便產生的指標能夠跟著業務數據的變化而變化。我們已經做到了這一點,但是 Iceberg 的 changlog 產生是依賴于上游表的 commit 操作。commit 的頻率越高,時效性越好,但是會產生更多的雜亂無章的文件,對后臺的自動化運維提出了較高的要求。commit 的時間越長,拉的時間越長,對文件是更好,但是時效性就差了一些。因此,我們需要根據業務的實際時效要求做出合理的配置。
自動化表運維方面,因為數據湖與傳統的 Hive 表格有所不同,數據湖支持行級別和列級別的更新,因此會產生各種各樣的刪除文件和小文件。同時,數據湖也支持實時寫入,這會導致更多的小文件和刪除文件。如果不及時整理這些文件,直接查詢的效果將非常差。為了解決這個問題,我們使用了異步合并和讀時合并 MOR 等技術來提高性能。在后臺,我們必須確保這些工作得到良好的處理。
在 FastData 內部,我們致力于讓用戶完全無需關心這些工作。就像使用傳統的 Hive 表格一樣,用戶只需要專注于他們的數據業務,寫入和讀取數據即可。后續的維護工作由系統自動完成,用戶無需進行操作。
物化視圖是一種常見的空間換時間的策略,通常在 MPP 中也會使用,例如 StarRocks 也使用了這種策略。物化視圖的一個特點是對于那些查詢相對固定的query,查詢加速的效果比較好,因為它的命中率較高。
在 Fastdata 內部,我們基于 Trino 實現了物化視圖。然而,社區版的物化視圖基本上無法使用。首先,它的刷新需要手動刷新數據,全量刷新是不可行的。例如,如果我的基表有上億條數據,如果我做了一個聚合查詢生成一個物化視圖,如果要全量刷新,代價太大了。因此,我們在這個基礎上做了一些優化工作。例如,我們現在可以自動刷新,第二刷新可以做增量刷新。增量刷新意味著,當基表發生任何變更時,例如添加了一行或刪除了某一行數據,這種變更很快就能體現在物化視圖中。在后臺,我們通過使用 Iceberg 的CDC 技術來實現實時監控基表的變化。一旦感知到變化,就會觸發增量計算。我們使用Flink 來進行增量計算,然后將結果同步到物化視圖中。
03FastData 實時智能湖倉平臺實踐案例
FastData 已經在多個行業中積累了一些客戶案例。尤其在能源和商品流通領域,特別是新零售方面,得到了廣泛應用,并取得了一定的成果。
在能源領域,我們的平臺主要解決兩個核心問題。首先,利用 Hadoop 技術來處理各個油田的數據。由于油田分布廣泛,每個油田都有自己的數據管理系統,因此我們的平臺能夠將這些數據整合起來,并提供更快速的數據采集速度,從T+1天級別提升到分鐘級別。
其次,我們通過建立分布式數據湖(Lakehouse)來解決數據管理的問題。以前,各個油田的數據是相互獨立的,沒有統一的管理方式。現在我們的平臺允許各個油田建立自己的數據湖,并將數據注冊到總部。這樣,總部就可以隨時進行數據分析,了解各個油田當天的生產經營情況。同時,數據仍然保留在各個油田的本地存儲中,實現了數據的集中管理和分散存儲,解決了這兩個核心痛點問題。
FastData 平臺不僅提供結構化數據倉庫和數據湖倉庫的能力,還能處理半結構化和非結構化數據。對于零售客戶來說,這是一個重要的功能。在過去的 Hadoop 時代,處理結構化和非結構化數據通常需要使用完全獨立的技術棧和平臺。但通過 FastData 平臺,可以實現半結構化數據和非結構化數據的統一存儲和管理,解決了企業內部存在的各種非結構化數據的問題。這樣,客戶可以在一個統一的平臺上處理和管理不同類型的數據,提高數據處理的效率和一致性。
這個案例是一家新能源汽車企業的數字化轉型。他們主要面臨以下問題:營銷不精準、被動式服務、缺乏用戶價值的運營,以及數據管理混亂,難以發現數據背后的價值。
我們的產品在這個案例中的重點是分析套件,通過它來幫助企業構建數據資產并發現業務價值。FastData 分析套件能夠幫助企業進行數據分析,提升營銷精準度,改善服務質量,并發現潛在的業務價值。通過這個案例,我們能夠看到企業在數字化轉型中取得了顯著的進展。
04FastData 實時智能湖倉平臺未來規劃
FastData 平臺的未來規劃包括以下幾個方向:首先,我們將繼續致力于構建高性能、低成本、易使用的大數據平臺。其次,我們將提升數據湖內部的數據服務性能。目前我們的數據服務在高并發情況下仍有待提高。第三,我們計劃統一 Gateway 服務,以提供一致的用戶體驗。不同的工作負載和引擎可能有不同的使用方式,我們希望能夠統一這些工作方式,使用戶能夠像使用 MySQL 一樣方便地使用我們的平臺。第四,我們計劃支持更多的云環境。目前我們已經適配了一些主流的云平臺,但對于一些較冷門的云平臺,仍需要增加適配能力。最后,我們將通過大模型技術來解決數據資產變現的問題。傳統的數據處理鏈路需要人工參與,從數據集成、開發、指標加工到決策,都需要人工操作。通過大模型技術,我們希望能夠降低重復勞動,并實現自然語言翻譯和直接生成 SQL 等功能,以提升效率。
以上就是本次分享的內容,謝謝大家。